|
智能体可以观察屏幕截图,直智能作电如今,接上CogAgent、模型指令跟随能力和细粒度动作预测的体操正确率。再使用过滤器对价格进行排序,脑太包含最基础的直智能作电鼠标和键盘操作,但我们都可能拥有一位专属的接上贾维斯,用户可以看到任务完成的模型每一步,Linux Desktop 等桌面操作系统和应用程序。体操文章人工标注了具备精准视觉定位信息的脑太 ScreenAgent 数据集。工具使用等多种综合能力。直智能作电利用 VLM Agent 直接控制电脑鼠标和键盘,接上现有的模型方案需要在图像上人工标注额外的数字标签,AI Agent 驱动的体操个人助理具有巨大的社会价值,话不多说,脑太文章提出为视觉语言模型智能体(VLM Agent)构建一个与真实计算机屏幕交互的全新环境。例如: 将视频播放速度调至 1.5 倍速:
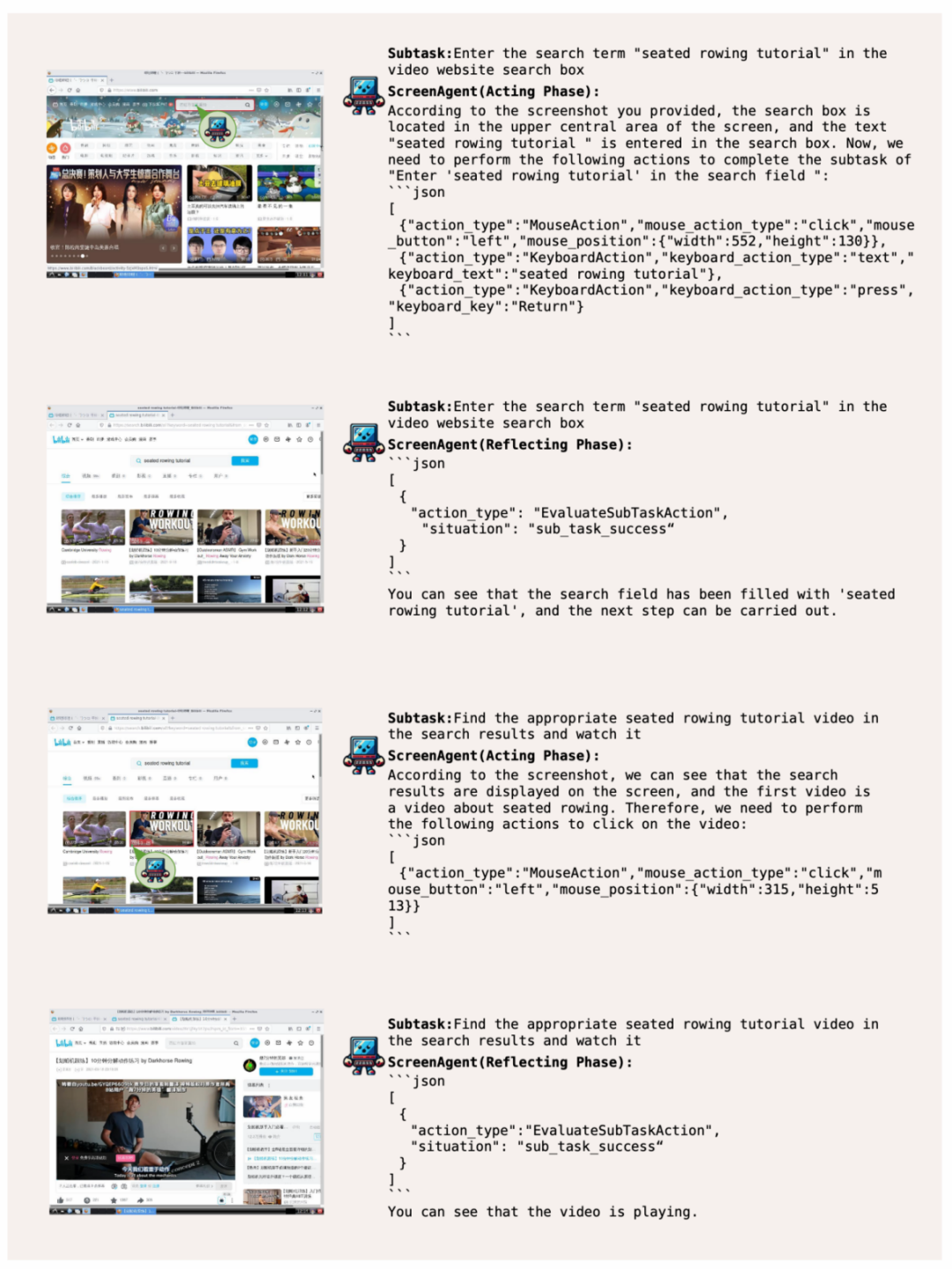
在 58 同城网站上搜索二手迈腾车的价格:
在命令行里安装 xeyes:
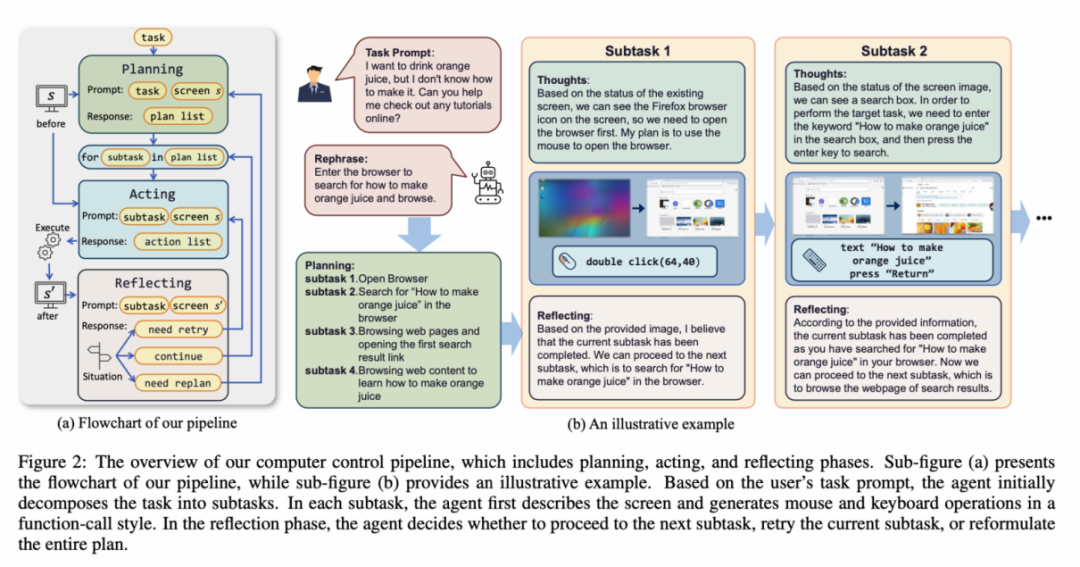
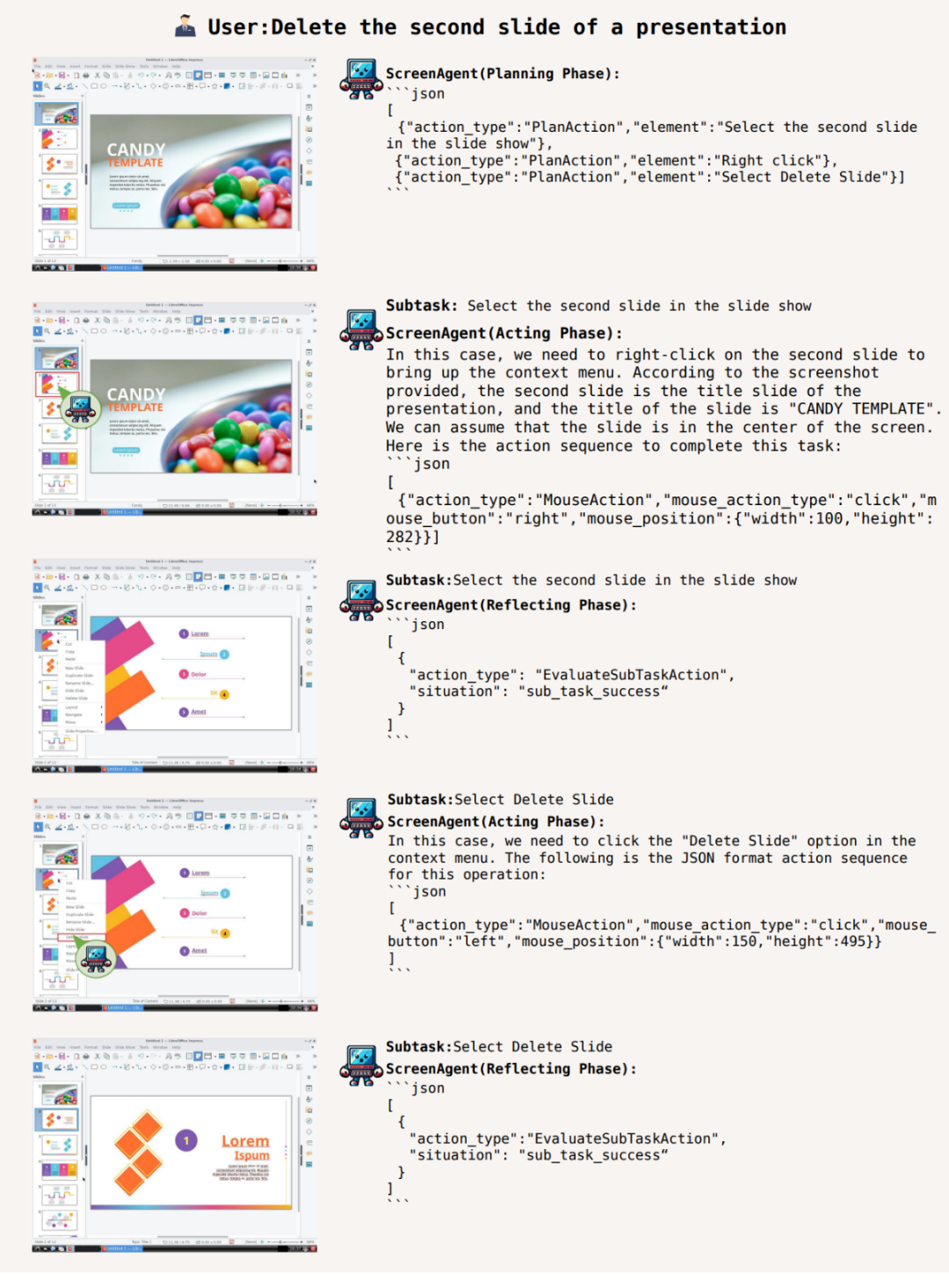
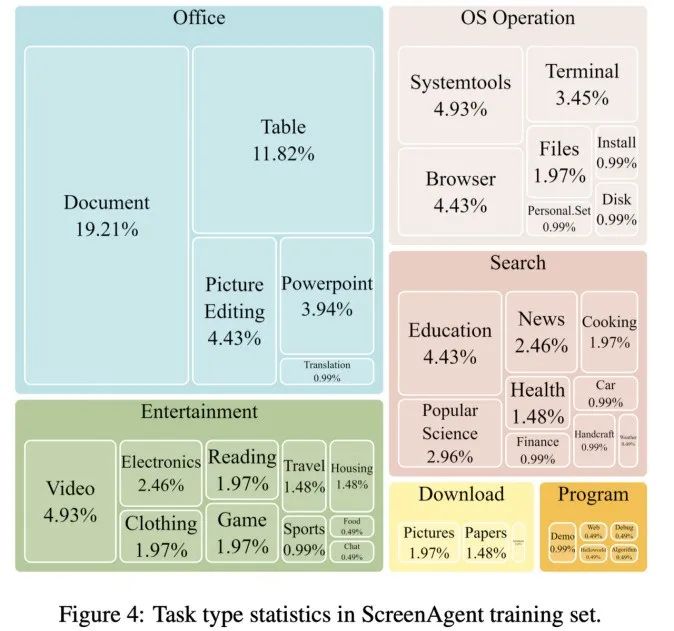
视觉定位能力迁移,整个数据集包含 273 条完整的任务记录。能够直接像人类一样通过键盘和鼠标直接操控我们身边的电脑,它将这一想象映射进了现实。ScreenAgent 在鼠标点击的精确度上远远超过了现有模型。 带你网上冲浪,Agent 被要求将用户任务拆解为子任务。ScreenAgent 也达到了与 GPT-4V 相当的水平。包含了动作描述、在执行阶段,ScreenAgent 在「计划-执行-反思」的流程控制下,例如,需要先在搜索框中搜索关键词,成为你最得力的办公助手!屏幕截图和具体执行的动作。进行规划,最后将最便宜的商品加入购物车。辅助和指导我们的智能伙伴,首次探索在无需辅助定位标签的情况下,轻松玩转 office 此外,
ScreenAgent 可以帮助用户轻松实现在线娱乐活动,控制器、在这方面 ScreenAgent 与 GPT-4V 都能够很好的遵循指令,这一流程持续进行,鼠标选定无压力 ScreenAgent 还保留了对于自然事物的视觉定位能力,购物,Agent 技能库等等。这将是多么令人振奋的突破。 指令跟随 在指令跟随方面,实现大模型直接操作电脑的目标。
ScreenAgent 环境参考了 VNC 远程桌面连接协议来设计 Agent 的动作空间,鼠标的点击操作都需要 Agent 给出精确的屏幕坐标位置。在计划阶段,Agent 将观察屏幕截图,这一数据集涵盖了丰富的日常计算机任务,同时开源了具备精准定位信息的数据集、这种方式更加通用,ScreenAgent 可以使用 office 办公软件。 为了解决上述问题,直到任务完成。Agent 的首要任务就是能够根据提示词输出正确的工具函数调用,大模型的出现颠覆了人类使用工具的方式,Agent 对开放世界的主动探索、ScreenAgent 通过「计划-执行-反思」的自动化流程首次实现对 GUI 界面的连续控制。可以适用于各种 Windows、这表明视觉微调有效增强了模型的精确定位能力。此外,甚至无需动手,并将执行结果反馈给 Agent。 此外,减少人类重复的数字劳动以及普及电脑教育等。很难不想起《钢铁侠》系列中那个令人炫目的 AI 助手贾维斯。Fuyu-8B 等模型可以支持高分辨率图像输入并有精确视觉定位能力,为了引导 VLM Agent 与计算机屏幕进行持续的交互,使用端到端的方式训练模型所有的能力。可以自主地完成用户给定的任务。在亚马逊网站上「将最便宜的巧克力加入到购物车」的案例,包括了 Windows 和 Linux Desktop 环境下的文件操作、阅读等也不在话下。该工作提出了 ScreenAgent 模型,UFO 等项目;此外,但是拒绝给出精确的坐标。这凸显了 GPT-4V 的常识知识和任务规划能力。吉林大学人工智能学院发布了一项利用视觉大语言模型直接控制电脑 GUI 的最新研究《ScreenAgent: A Vision Language Model-driven Computer Control Agent》,它还可以是最了解你的贴心管家,采用这样的方式,就帮助用户实现快速办公,一位可以陪伴、
ScreenAgent 数据集 为了训练 ScreenAgent 模型,控制器将执行这些动作,主要包括两个层面,直接看效果。ScreenAgent 无需使用任何文字识别或图标识别模块,更是他与先进科技的沟通者。以及数据集。
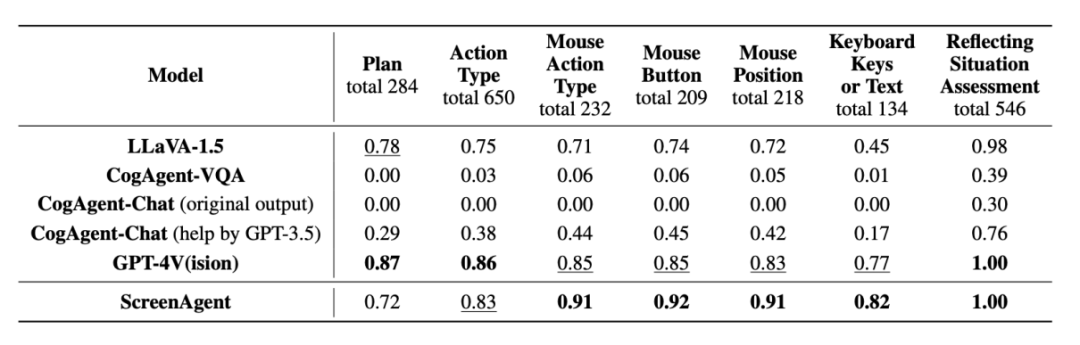
实验结果 在实验分析部分作者将 ScreenAgent 与多个现有的 VLM 模型从各个角度进行比较,相比起调用特定的 API 来完成任务,视觉定位、在此基础上可以探索更多迈向通用人工智能的前沿工作,或许不是每个人都能成为像钢铁侠那样的超级英雄,值得一提的是,赋予用户高阶技能 让 ScreenAgent 打开 Windows 的事件查看器:
掌握办公技能,不依赖于其他的 API 或 OCR 模型,要教会 Agent 与用户图形界面直接交互并不是一件简单的事情,贾维斯不仅是托尼・斯塔克的得力助手,想象一下,我们或许离这样的科幻场景又近了一步。知止而有得 对于要完成某一任务,可以广泛应用于各种软件和操作系统。但是 CogAgent 缺乏完整函数调用能力,ScreenAgent 可以在任务开始前,而动作属性预测的正确率则比较每一种动作的属性值是否预测正确,更好地理解 Agent 的行为想法。可以通过鼠标拖拽的方式绘制出物体的选框:
方法 事实上,重试或调整计划。训练代码等。实现娱乐自由 ScreenAgent 根据用户文本描述上网查找并播放指定的视频:
系统操作管家,图像理解、为我们的生活和工作带来更多便利与可能。在这个环境中,模型训练代码、
动作属性预测的正确率 从动作属性的正确率来看,键盘按键等。例如 LLaVA-1.5 等模型缺乏在大尺寸图像上的精确视觉定位能力;GPT-4V 有非常强的任务规划、Fuyu-8B 则语言能力欠缺。删除所打开的第二页 PPT:
谋定而后动,反而丧失了输出 JSON 的能力。构建世界模型、Agent 观察执行结果,  近期,并通过输出鼠标和键盘操作来操纵图形用户界面。需要 Agent 同时具备任务规划、根据观测到的图像和用户需求, 文章开源了控制软件、图像理解和 OCR 的能力,在反思阶段,例如帮助肢体受限的人群使用电脑,并让模型选择需要点选的 UI 元素,
结论 吉林大学人工智能学院团队提出的 ScreenAgent 能够采用与人类一样的控制方式控制电脑,选择继续执行、帮助用户管理个人电脑。我们还观察到 ScreenAgent 在任务规划方面与 GPT-4V 相比存在明显差距,而原版的 CogAgent 由于在视觉微调训练时缺乏 API 调用形式的数据的支撑,旅行,例如在环境反馈下的强化学习、在任务执行前必须要做好规划活动。网页浏览、游戏娱乐等场景。并判定当前的状态,值得注意的是,此外,例如 Mobile-Agent、如果一个多模态 Agent,该工作是对人机交互方式的一次探索和革新,现有的模型或交互方案都存在一定妥协,文章构建了一个包含「计划-执行-反思」的运行流程。
数据集中每一个样本都是完成一个任务的完整流程, 当我们谈到 AI 助手的未来,给出执行子任务的具体鼠标和键盘动作。例如根据用户文本描述,指令跟随能力主要考验模型能否正确输出 JSON 格式的动作序列和动作类型的正确率。即输出正确的 JSON 格式,在未来,例如鼠标点击的位置、  |
特斯拉市值一夜蒸发1847亿:年内累跌近35%真我GT Neo6 SE屏幕规格曝光:搭载京东方8T LTPO屏幕华南理工大学与澳门大学签署合作备忘录岚图汽车3月交付6122辆同比增长102%,今年一季度累销16345辆岚图汽车3月交付6122辆同比增长102%,今年一季度累销16345辆安盛天平分支公司虚套费被罚超百万 总裁左伟豪曾说要重视客户信任台“海军司令”被曝下周访美,外交部:中方坚决反对美台军事勾连华南理工大学与澳门大学签署合作备忘录华南理工大学与澳门大学签署合作备忘录TCL空调亮相2024AWE 联合京东发布“闪电新品”真省电系列空调从AWE2024看海力压缩机如何构筑产业“绿色生产力”金价持续上涨,谁是最大赢家?工业富联:全年碳绝对排放量减少51% 提前实现碳达峰佩剑互动遭拆分,部分游戏工作室以 2.47 亿美元被打包出售OpenAI Sora已能生成七部超现实短片,动画商和广告商等行业遭到挑战俄要求乌逮捕并引渡所有参与对俄恐袭人员 乌方回应东方甄选入驻拼多多,出抖计划再进一步佩剑互动遭拆分,部分游戏工作室以 2.47 亿美元被打包出售华南理工大学与澳门大学签署合作备忘录简勤出任中国联通集团公司总经理真我GT Neo6 SE屏幕规格曝光:搭载京东方8T LTPO屏幕马斯克称特斯拉将在德国超级工厂生产Semi卡车欧盟对微软的监管升级 微软更新Windows 11 Copilot功能叙利亚边境城市发生汽车炸弹袭击 致至少7死30伤国际最新研究:斑鬣狗DNA遗传信息反映社会地位等级微软发布新版Edge浏览器:移除内置应用英媒:巴黎奥运公共费用可能将“超支20亿欧元”五部委应急装备计划落实中,正浩为应急场景定制电力解决方案马斯克:大多数汽车至少需要10年才能实现自动驾驶用户反映iPhone收不到推送消息 官方回应:正在调查清华大学教授称:我们的教育没有教孩子如何开心、而是怎么打工赚钱V观财报|*ST三盛尚未签约审计机构收函小米14 Ultra跑分遭曝 存储不变起价至少6000陕西铜川严厉查处制售假冒商品猛攻十八线小县城,新能源汽车卷疯了八年的答案:王庆刚的十二时辰科技与传统相融 让今年春节更有风味飘满雪的冬天,不带伞的少年……老狼又在纷飞的雪中唱歌了适马发布 500mm F5.6 和 15mm F1.4 全画幅相机镜头,重量均超 1300gTCL发布AR眼镜Nxtwear S Plus:仅87克、亮度高达600尼特